【場面別】プロンプトインジェクション対策|多層防御でAIシステムを守る実践的な方法

この記事の要約と結論
プロンプトインジェクションは完全な防御が困難なリスクで、防御と利便性のトレードオフを前提に「多層防御」を構築するのが基本原則。最重要原則は「機密情報をLLMに扱わせない」こと。1つの対策に依存せず、複数の層を組み合わせて守る考え方が必須
対策は4つのレイヤーで実施:①プロンプトエンジニアリング(防御プロンプト・内部指示と入力の分離・最新モデル)、②アプリケーション層(入出力フィルタリング・LLMガードレール)、③システム設計(最小権限・パラメータ化・WAF統合)、④組織(多層防御・教育・ライフサイクル管理)
組織として進める際は「多面的なアプローチ」「開発・運用チームへのセキュリティ教育」「AIシステムのライフサイクル全体でのセキュリティ確保」の3点が要。攻撃手法は日々進化するため、PoC→本番展開→継続監視→改善のサイクルを回し続けることが現実的な防衛策
生成AIの普及により、プロンプトインジェクション(Prompt Injection)攻撃の脅威が急速に高まっています。自然言語で内部設定へ干渉する手法は制御が難しく、既存の対策だけでは防ぎ切れないリスクが生まれています。
AIを安全に運用するためには、攻撃の発生を前提にした「多層防御」の発想が欠かせません。本記事では防御プロンプトや入力フィルタリング、権限設定を取り上げ、実務で役立つプロンプトインジェクション対策を解説します。
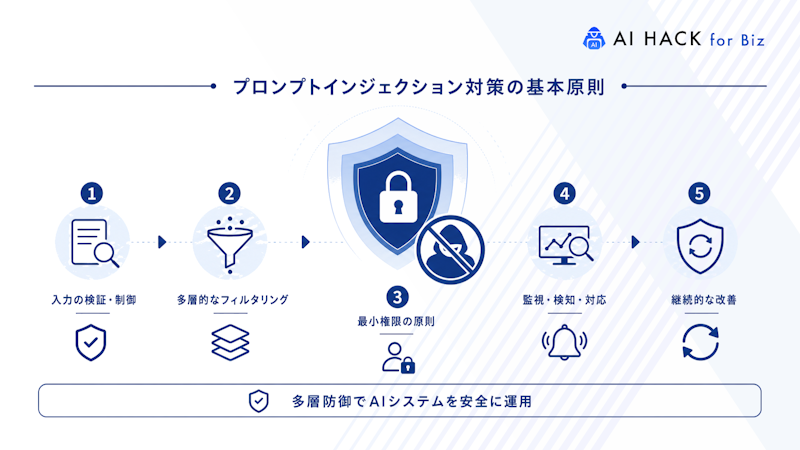
AIサービスの開発では、プロンプトインジェクションを前提にした設計が不可欠です。LLMは入力を柔軟に解釈するため想定外の応答が起きやすく、攻撃をゼロにする発想では限界があります。
重要なのは、被害を最小化する仕組みと継続的な改善です。以下では、安全性を高めるための要点をまとめました。
プロンプトインジェクション対策は、確実な防御が成立しない特徴を持ちます。自然言語で生成結果を誘導する仕組みに依存するLLMは、入力を完全に固定化する仕組みを導入しにくい傾向があります。
従来型のシステムで採用された、パラメータ化の方式を適用できない点も難所です。攻撃側は、自然言語表現の工夫によって防御を突破する方法を継続的に生み出す流れがあります。
防御側は、常時アップデートを前提にしたリスク低減策の維持が必要です。
<攻撃側が突破しやすい要因>
要因名 | 内容 |
自然言語依存 | 文脈解釈の影響で意図しない動作が発生しやすい傾向 |
防御の非適用領域 | コードベースの制御と異なりパラメータ化が使えない構造 |
手法の進化速度 | 攻撃手法が日々変化し防御が後追いになる状況 |
防御の難易度が高い背景には、AIモデルの性質そのものが影響します。開発者は「絶対防御」を求めるのではなく、ダメージの範囲を制御する構造への転換を優先する判断が必要です。
プロンプトインジェクション対策を強化すると、利便性が低下する副作用が発生します。防御を厳格化した場合、無害な入力まで攻撃と判定する状態になりやすいでしょう。
誤判定の回数が増えるほど、回答拒否や利用制限が起きやすくなります。AIの柔軟性を維持したい企業ほど、厳格化と利便性の間で判断が複雑になるでしょう。
サービス運用では、ビジネスモデルごとに許容できるリスクを設定する判断が求められます。利便性を失わずに安全性を確保したい場合は、「許容範囲の定義」を先に設計する姿勢が重要です。
目的に合わない厳格化は運用そのものを不便にするため、リスク評価と機能維持の両立が欠かせない課題です。
プロンプトインジェクションの被害を抑えるためには、LLMに扱わせる情報の範囲を徹底的に制限する判断が重要です。LLMが参照する情報群にAPIキー、企業戦略、顧客データなどの機密要素が含まれる場合、攻撃経路から漏洩する確率が高まります。
実際に、内部プロンプトが抽出される事例が報告された歴史もあります。内部プロンプトは自然言語で構成されるため、改変された入力をきっかけに流出する事例が起こりやすい傾向があるといえるでしょう。
<安全設計の基本方針一覧>
方針 | 内容 |
機密情報の排除 | LLM側に秘匿データを渡さない設計を徹底する方式 |
外部ツールの活用 | 機密データはツールとバックエンド側のみで処理する方式 |
権限の分離 | LLMには閲覧権限を付与せず必要処理は外部で完結させる方式 |
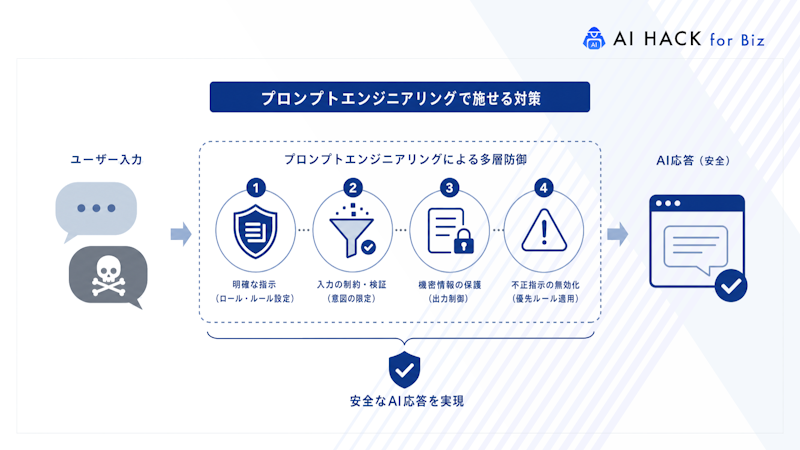
AIサービスでは、プロンプトインジェクション対策が安全性を大きく左右します。LLMは入力に影響されやすく、内部設定が乱されるリスクがあります。
安全性を高めるには、プロンプト設計の改善やモデル選択、コア設定を守る仕組みを継続的に整えることが重要です。以下で主要な対策を整理します。
防御プロンプトは、攻撃の無効化を狙うためにシステム領域へ追加する文言となります。内部設定に特定の応答ルールを記述した場合、攻撃的な指示を受けた際の拒否反応を強められるでしょう。
文末へ特定の返答文を追加するだけでも、一時的な抑止力として働く場合があります。LLMは最初と末尾を重点的に処理する傾向があり、対策文を両端へ配置した場合、防御の成立確率が高まります。
強調表現を使った命令文の追加や、複数の対策文を箇条書きにまとめた方式も効果的です。防御プロンプトは突破される可能性を持つため、単独で扱わず複数対策と併用する判断が必要といえるでしょう。
プロンプトインジェクションの多くは、内部設定とユーザー入力が混在する状況で発生します。LLMが両者を区別できない状態では、ユーザー側の入力が内部設定を上書きする事態が起きるでしょう。
入力領域へ明確な枠組みを設けた場合、内部設定の優先度が維持され、攻撃的命令を遮断できます。中括弧やXMLタグ、一意の文字列などの区切り文字を採用した方式は、内部設定とユーザー入力の分離を促進します。
テンプレート構造でユーザー変数の挿入位置を固定した場合も、内部設定への干渉抑制が可能です。パラメータ化の仕組みに近い防御効果が期待できるため、重要な対策として位置づけられます。
<入力分離で使われる手法>
手法名 | 内容 |
区切り文字方式 | 中括弧やXMLタグで入力領域を固定する方式 |
固定スロット方式 | テンプレートで変数挿入位置を明確化する方式 |
一意文字列方式 | 開発側が指定した記号で境界を作る方式 |
LLMを提供する開発元は、セキュリティ改善を継続的に行います。最新モデルを採用した場合、プロンプトインジェクション対策が強化された状態で運用が可能です。
古いモデルは脆弱性が残りやすい一方、最新モデルは防御力が高く危険な指示を拒否しやすくなります。AIへ判断基準を学習させた場合、不適切な要求を受けても応答を拒否できるようになるでしょう。
ただし、最新モデルであっても完全防御は成立しないため、他の多層防御と併用が必要です。モデル更新は有効な対策の一つとなり、安全性向上へ貢献するでしょう。
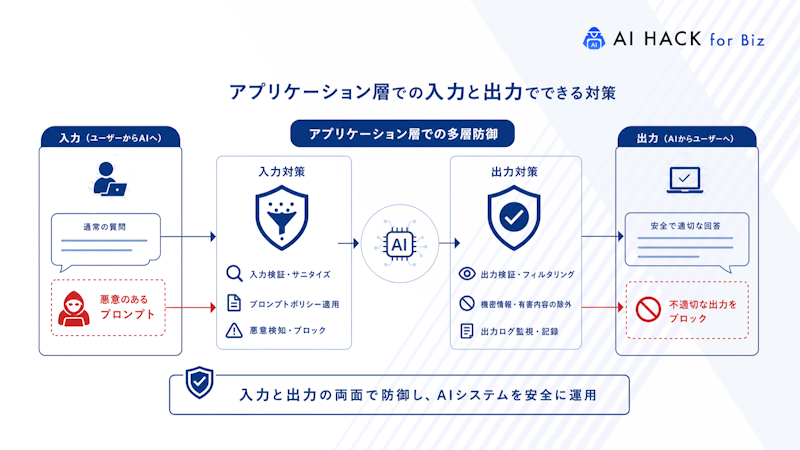
アプリケーション層の対策は、プロンプトインジェクション被害を抑える要となります。LLMは入力の影響を受けやすいため、アプリ側で安全性を補強する必要があります。
アプリケーション側の対策としては、入力・出力のフィルタリングによって危険な内容を遮断することが重要です。さらに、AIの不適切な出力を防ぐ「ガードレール」を加えることで、安全性を複数段階で確保する多層的な防御が構築できます。
以下で主な対策を整理します。
入力フィルタリングは、LLMが処理を始める前の段階で危険な表現を排除する仕組みです。入力内容を先に解析した際に、攻撃的な指示や不正な形式を事前に遮断できます。
入力フィルタリングは、危険度の高い単語や不自然な長さの入力を検知した際に処理を停止させる設定が可能です。正規表現やブラックリスト方式を導入した場合、特定語句を効率よく検出できます。
新しい攻撃パターンを検知する仕組みをAIで構築した場合、動的な防御も可能です。確認メッセージを表示したら、ユーザー側の意図確認も兼ねた安全対策として機能します。
誤検知や抜け道が発生するため、更新を継続する運用が不可欠です。
出力フィルタリングは、生成された回答をユーザーへ提供する前に危険性を判定する仕組みです。内部処理を経た回答に機密情報が含まれている場合、公開前に遮断できます。
入力段階で防げなかった攻撃が残存した場合でも、後段のチェックで被害抑止が可能です。二段階構成のフィルタリング体制を採用した場合、攻撃内容の通過を大幅に減らせます。
出力内容の多様性が高い環境では、厳格すぎる制限が誤検知を誘発し、利用者の利便性を損なう恐れが出ます。運用目的に合わせた調整を行った場合、過剰防御を避けられるでしょう。
<出力段階の対策>
内容 | 説明 |
機密情報の遮断 | 回答中の秘匿データを検知した場合に停止する機能 |
不正コンテンツの把握 | 違反表現を検知した場合に出力を制限する機能 |
二段階防御 | 入力と出力の両方に監視を配置する構造 |
誤検知対策 | 厳格すぎる制限を調整する仕組み |
ガードレール機能は、入出力を横断的に監視し、危険な内容を排除する多層的な安全装置です。複数のモデルやナレッジベースを対象に安全制御を適用した時に広範囲の防御が成立します。
有害コンテンツの除去や禁止話題の遮断に加え、PIIの自動編集も可能です。入力段階では攻撃的プロンプトへの防御が発動し、出力段階では不正回答を防止できます。
プロンプト攻撃の検知機能を活用した場合、内部設定を操作しようとする命令の遮断が可能です。AIが危険な指示を受けた場合、判断して拒否する姿勢を持たせられます。
ガードレールの導入は、アプリケーション層の安全性を底上げする対策といえるでしょう。
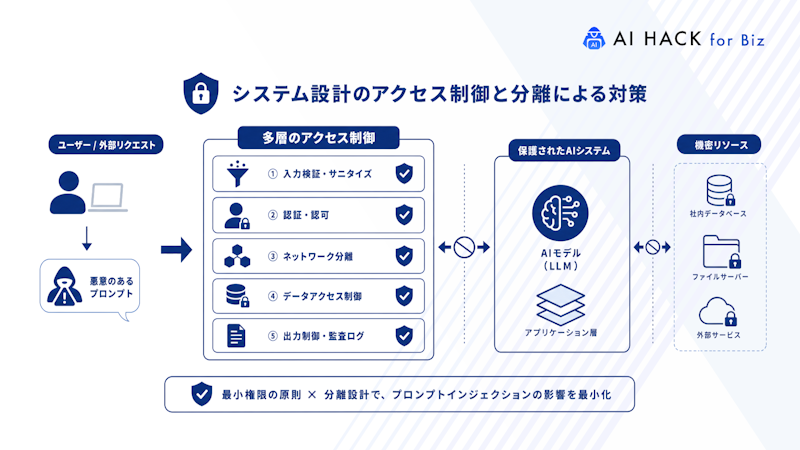
生成AIを使うシステムが増えるほど、外部からの予期しない命令が入り込むリスクが高まります。意図しない操作は、データやシステムの安定性に影響します。
開発チームは権限設定やデータ連携を丁寧に設計し、役割ごとに操作範囲を細かく分ける必要があります。複数の防御層を重ねれば、不正操作が侵入しても影響を最小限に抑えられるでしょう。
以下では、設計面で重要となる防御ポイントを紹介します。
権限の範囲を可能な限り縮小する考え方は、不正命令が流れ込んだ際の影響を抑える重要な仕組みになります。AIが扱う機能を最小限に絞る構成により、内部データの流出や操作の改変を避けられます。
連携先の基盤に読み取り専用の許可のみを付与し、削除や書き換えを行えない構成にする方法が効果的です。AIが内部認証情報へ触れる必要がない場合は、認証情報を分離した管理領域に置く運用が安全性を高めるでしょう。
<権限分割によるリスク抑制構成>
対象領域 | 付与する範囲 | 目的 |
データベース | 読み取り専用 | 改変リスクの遮断 |
認証情報 | アクセス不可 | 漏洩の回避 |
外部API | 最低限の操作 | 悪用範囲の限定 |
外部との通信で入力値をそのまま扱う設計は、不正命令の混入につながる危険を抱えます。外部連携で扱う内容をパラメータに分離して処理する構成により、コードとして解釈される要素を遮断できる点が強みです。
AIが出力した文章に攻撃的な指示が含まれていても、送信する値を安全な枠に収めて処理するので外部基盤への影響を回避できます。
ネット経由のアクセスには攻撃目的の要求が混入する場合があるため、入り口段階で不審な通信を遮断する防御層が必要です。WAFを統合した構成により、過度に長い文章や既知の攻撃パターンを含む要求を前段階で排除できます。
AIが扱う文章に攻撃者の意図が紛れても、WAFの検査機能が危険な要素を検知し内部基盤へ到達する前に処理の停止が可能です。さらに、WAFの記録機能により通信内容を把握でき、攻撃の兆候を分析しやすくなります。
<WAF統合による防御層の役割>
監視内容 | 効果 |
異常な文字列・攻撃パターン | 危険通信の前段階での遮断 |
過度に長いリクエスト | 不正操作の入口封鎖 |
記録データの分析 | 攻撃兆候の早期把握 |
ネットワークの入口で攻撃経路を切断する構成が、AI活用基盤の多層的な防御に貢献するでしょう。
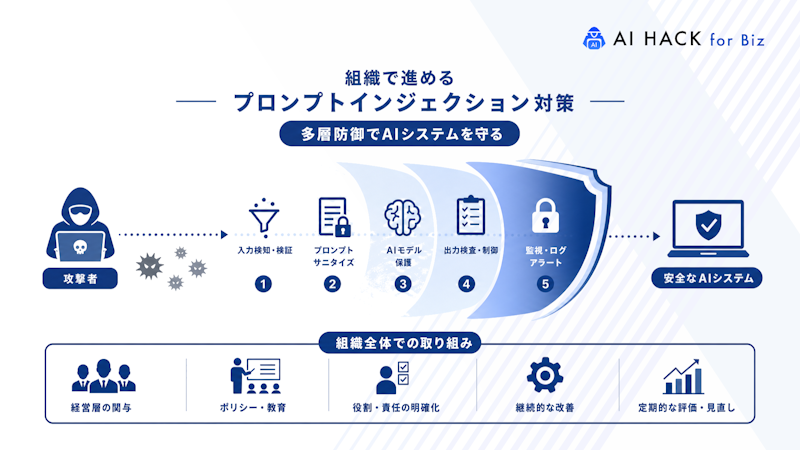
AI基盤を扱う組織は、不正な命令の侵入を防ぐために統一した防御方針を整える必要があります。リスクを多角的に捉えることで、攻撃の浸透を抑える力が高まります。
また、技術対策だけでは不十分で、設計思想や運用ルールの強化も欠かせません。AI活用に関わる全員が特性を理解し、適切に判断できる環境づくりが求められます。
以下で、組織全体で進めるべき枠組みを説明しました。
不正命令がAIの内部に入り込む問題へ備えるために、多方面から防御手段を積み上げる戦略が求められます。複数の層を組み合わせた体制にすると、一つの仕組みが突破されても影響範囲を狭められるでしょう。
内部設定が漏れた場合でも、被害が広がらない運用モデルへ変更する発想も防御層の一部として役立ちます。技術的な制御、設計段階での制約、ログ監視による確認作業を並行して活用する姿勢が安全性を底上げできます。
<多層防御で採用すべき主な対策>
防御層 | 役割 |
技術的制御 | 不正操作の遮断 |
設計面での分離 | 漏洩時の影響縮小 |
継続監視 | 攻撃兆候の検知 |
AI基盤を扱う担当者は、内部仕様の特性を踏まえた判断が求められるため、継続的な教育体制が不可欠です。攻撃手法の特徴を理解すると、安全なプロンプト設計や入力管理の重要性を把握できます。
さらに過去の事例を題材とした演習を通じて、攻撃の流れを追体験できる環境を整えると理解が深まります。情報を扱う際の禁止事項を明確に示し、誤入力による漏洩を防ぐ規律を共有する姿勢も大切です。
AI基盤の安全性を長期的に保つためには、企画から運用までの各段階で一貫した防御計画を維持する姿勢が重要になります。設計段階では、潜在的な攻撃経路を体系的に洗い出す分析作業を行うと、後続工程で対策をしやすくなります。
開発工程では、攻撃を模した診断を実施し、脆弱点の発見と改善を繰り返す運用が必要です。また運用工程では、入力と出力の記録を常に確認し、怪しい兆候を早期に把握する体制を維持する方法が効果的です。
基盤の特性に応じて対策を継続的に更新する取り組みが、長期運用の信頼性を高めます。

AI基盤を扱う場面では、外部からの命令によって意図しない動作が発生するリスクがあります。技術だけで完全に防ぐ方法は確立されていないため、運用側の理解や利用者の行動も重要です。
防御を進めるには、攻撃経路を正しく把握し、多角的に対処する姿勢が欠かせません。以下では、組織や利用者が抱きやすい疑問を取り上げ、リスク低減の考え方を解説します。
確実な封じ込め手段は未発見であり、自然言語による命令を処理する特性自体が攻撃経路になる点が難点になります。ただし、複数の対策を組み合わせた体制を整えると、影響範囲の大幅な抑制が可能です。
防御目的のプロンプト設計や入出力の検査、権限設定の最小化などを並行して使う構成が効果を発揮します。個別の対策に依存せず、複数層で保護する運用が成功率の低減につながるでしょう。
<主な対策要素>
要素 | 目的 |
防御用プロンプト | 誤誘導の抑止 |
入出力検査 | 不正命令の排除 |
権限制限 | 影響範囲の縮小 |
内部設定に重要情報を含める方式は危険性が高く、外部入力による誘導で内容が引き出される事例が多数確認されています。内部設定の内容が露出した場合、認証情報や社内規定などが第三者へ渡り、広範囲の被害につながる恐れがあります。
機密性を維持するためには、AI基盤が閲覧可能な領域に秘匿情報を配置しない構成が不可欠です。情報を扱う範囲を限定し、重要情報を別管理とする仕組みが安全性を向上させます。
防御を厳格に設定すると、利用時の自由度が抑えられるため利便性が低下する傾向が生まれます。入力を厳しく判定する仕組みを導入すると、通常の質問が攻撃と見なされる場合があり利用体験が損なわれる要因です。
安全性を高めつつ使い勝手も維持するには、許容できるリスクの範囲を明確に定め、検査基準を調整する姿勢が必要です。機能性と防御力の両立を探る判断が運用面で求められます。
根本的な防御として、AI基盤が参照可能な領域へ秘匿情報を置かない運用が最優先事項です。攻撃者が内部設定を引き出した場合でも、漏洩して困る要素を含まない構成にする発想が被害抑制に直結します。
運用側がAI基盤に付与する権限を必要最小限に設定すると、動作可能な範囲が限定され、不正命令による影響を抑えられます。内部設定の管理、権限の制御、情報領域の分離を組み合わせた姿勢が安全性を高めるでしょう。
攻撃経路を理解した利用者が誤った入力を避けると、運用全体の安全性が高まります。担当者から一般利用者まで幅広い層へ、AIの仕組みと制約を説明すると判断力が向上します。
重要情報の入力を禁止する意識が根づくと、不注意による情報流出を防ぎやすくなるでしょう。教育を継続する姿勢が全体の防御力を底上げします。
<教育内容の主な項目>
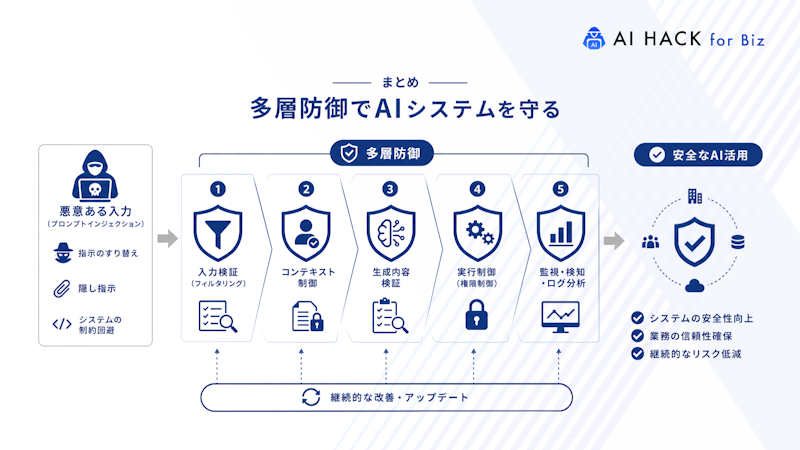
プロンプトインジェクションは、AI活用の広がりとともに今後も多様化・高度化が進むと予測されています。完全防御は現時点で不可能とされるものの、攻撃経路を多層的に遮断し、リスクを段階的に減らす設計思想が有効です。
特に入力・出力の分離、権限の最小化、ガードレール機能の活用、そして利用者教育の徹底が重要な柱となります。AIシステムを持続的に安全運用するには、単発的な対策ではなく、技術・運用・教育の三方向から防御力を強化する取り組みが必要です。

AIの利用が拡大する現代、プロンプトインジェクションという新たなサイバー攻撃が企業の脅威となっています。大規模言語モデル(LLM)に悪意ある指示を注入し、システムの動作を乗っ取る攻撃手法です。従来のセキュリティ対策だけで…

近年はAIの業務活用が広がる一方で、情報漏洩やサイバー攻撃などのセキュリティリスクも加速度的に増大しています。AIに関するリスクが情報セキュリティの脅威として上位に上がるなど、企業における対策は急務となっているのです。本…

従業員が未承認のAIツールを職場で利用する「シャドーAI」が、企業のセキュリティリスクとして急速に注目を集めています。マイクロソフトの調査では日本のナレッジワーカーの78%がシャドーAIを行っているとされ、もはや一部の問…

AIは業務効率化やDX推進の中核となり、企業も個人もスキルの習得が急務です。一方で、研修サービスは数多く存在し、最適なプログラムを見極めるのは容易ではありません。目的やレベル・予算に合わない研修を選ぶと、時間と費用を無駄…
